1. hello_world_main.c 분석
이 글의 최종적인 목적은 esp32로 와이파이, 블루투스 등의 기능을 이해하고 개발가능 하게 하는 것이다.
교수님과 상담중 받아온 esp32 보드로 진행한다.
esp32 는 크게 두 가지로 개발환경을 선택할 수 있는데
한가지는 아두이노를 이용하는 것이고
다른 한가지는 espressif 사에서 자체 개발한 esp-idf 를 이용하여 개발할 수 있다.
이 블로그에서 작성할 내용은 examples 디렉토리에 있는 예제들을 이용할 것이다.
이번 포스팅은 get-started의 hello_world 를 분석해 볼 것이다.

경로을 따라가 보면 main 에 hello_world라는 c파일이 존재한다.

이를 vscode에서 열어 보았다. 이는 일단 놔두고 이 프로그램을 빌드하여 플래쉬 해보겠다.

esp-idf 설치하고 나면 위와 같은 프로그램이 설치된다.
실행 시키면 와 같은 문구를 띄운다.
하라는 대로 idf.py build 를 하면 오류가 뜰 것이다.
작성자가 생각한 오류의 이유는 idf.py 라는 명령이 "esp-idf-v4.4.1"이라는 디렉토리에 없기 때문일 것이다.

저는 C:\esp_ex 라는 디렉토리를 만들어 hello_world 를 복사하여 진행했습니다.
이제 빌드가 되는 군요....

빌드가 된 후에
idf.py -p (PORT) flash 를 실행하라고 뜬다.

PORT는 장치관리자에서 찾을 수 있다.

테라텀이라는 단말 에뮬레이터를 통해 Hello world! 및 다른 정보가 출력되는 것을 볼 수 있다.
이제 본격적으로 어떻게 이 코드가 출력이 되는지에 대해 알아보자.

이 파일의 목적은 보통의 프로그래밍 예제들의 처음과 같이 "hello world!"를 출력하는 것이다.
line 18 은 넘기겠다.
line 21에서 esp_chip_info_t 라고 정의된 구조체를 선언 하였다.

이 구조체의 내부는 위와 같다.

model이란 멤버는 칩의 모델
즉, 어떤 기능을 수행할 수 있는지 모델마다 다르며 코어의 갯수 ,메모리 등을 결정하기 위함 일 것 같다.
현재 사용중인 모델은 esp32 모델로 model == 1 이다.

features란 이 칩이 와이파이, 블루투스, 802.15.4 프로토콜 등 을 지원하는지에 대한 정보이다.
메인 함수에서와 같이 chip_info.features를 위의 플레그들과의 &연산을 통해 확인 한다.
사용중인 esp32 모델은 BLE/BT를 모두 지원한다.

cores는 위 코드에서 듀얼코어인지 싱글코어인지 결정하게 되고 esp32모델은 듀얼 코어이다.
revision 또한 esp_efuse_get_chip_ver()을 통해 반환된다.
EFUSE_BLK0_RDATA3_REG 는 칩 시스템의 정보가 기록된 efuse고, 이를 레지스터에 읽어와 efuse_rd3에 저장한다.
memset을 통해 칩정보 구조체를 초기화 시킨 후 칩의 모델, 리비전, 코어 갯수, 어떤 통신을 지원하는지를 저장한다.
이는 hello_world_main.c의 line 22의 함수가 정의된 파일이다.



(여기서 spi_flash 란 시리얼 통신이 가능한 플래쉬 메모리 이다.)
line 31플래쉬 메모리의 크기를 구하기 위해 spi_flash_get_chip_size()함수를 이용하였다.
메인 함수의 line 32 에서는 플래쉬 메모리가 칩 외부에 있는지, 내부에 있는지를 알려준다.

line 35 에서는 이 응용프로그램이 사용할 최소한의 크기를 알려준다. 이는 약 0.3 MB 이다.
이 코드를 따라가며 알게된 것이 있다.
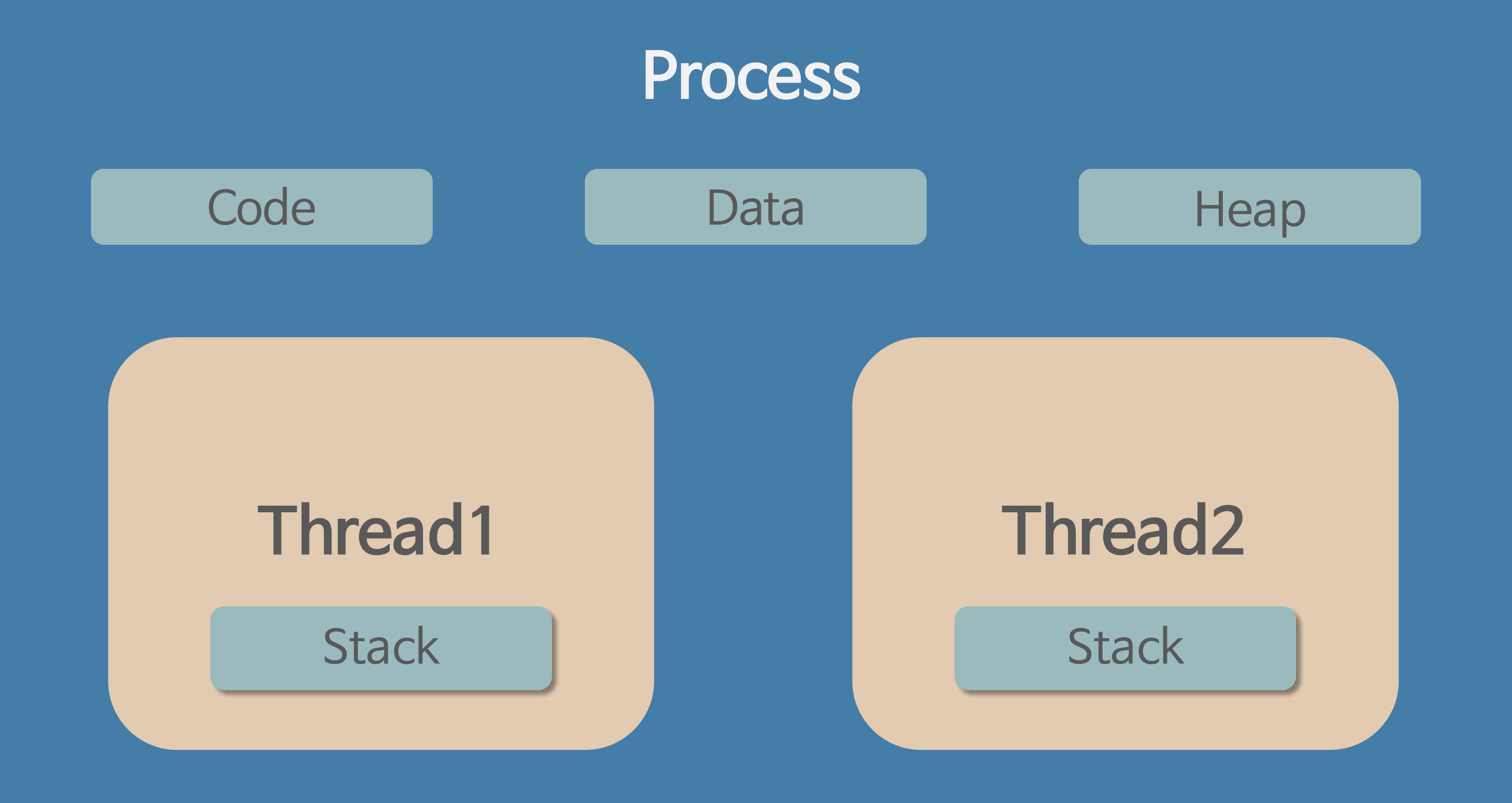
원래 알고있던 프로세스와 스레드의 관계는 위 그림과 같다.
하지만 esp32 에서는 multu_heap이라는 자료구조를 통해 각 스레드에 힙을 할당할 수 있다.
"Why Use Multiple Heaps?
Using a single runtime heap is fine for most programs. However, using multiple
heaps can be more efficient and can help you improve your program's performance
and reduce wasted memory for a number of reasons:
1- When you allocate from a single heap, you may end up with memory blocks on
different pages of memory. For example, you might have a linked list that
allocates memory each time you add a node to the list. If you allocate memory for
other data in between adding nodes, the memory blocks for the nodes could end up
on many different pages. To access the data in the list, the system may have to
swap many pages, which can significantly slow your program.
With multiple heaps, you can specify which heap you allocate from. For example,
you might create a heap specifically for the linked list. The list's memory blocks
and the data they contain would remain close together on fewer pages, reducing the
amount of swapping required.
2- In multithread applications, only one thread can access the heap at a time to
ensure memory is safely allocated and freed. For example, say thread 1 is
allocating memory, and thread 2 has a call to free. Thread 2 must wait until
thread 1 has finished its allocation before it can access the heap. Again, this
can slow down performance, especially if your program does a lot of memory
operations.
If you create a separate heap for each thread, you can allocate from them
concurrently, eliminating both the waiting period and the overhead required to
serialize access to the heap.
3- With a single heap, you must explicitly free each block that you allocate. If you
have a linked list that allocates memory for each node, you have to traverse the
entire list and free each block individually, which can take some time.
If you create a separate heap for that linked list, you can destroy it with a
single call and free all the memory at once.
4- When you have only one heap, all components share it (including the IBM C and
C++ Compilers runtime library, vendor libraries, and your own code). If one
component corrupts the heap, another component might fail. You may have trouble
discovering the cause of the problem and where the heap was damaged.
With multiple heaps, you can create a separate heap for each component, so if
one damages the heap (for example, by using a freed pointer), the others can
continue unaffected. You also know where to look to correct the problem."
멀티힙은 이와 같은 장점이 있는데
1,2. 만약 힙에 데이터 리스트가 있는데 그것을 여러 스레드에서 동시에 접근하려 한다면 프로그램 속도가 크게 느려질 수 있다.
3. 예를들어 연결리스트를 해제 하는 과정에서 단일힙은 개별적으로 해제하여 시간이 오래 걸리지만 멀티힙은 아예 연결리스트하나만을 위한 힙을 만들어 힙자체를 해제하여 시간이 절약된다.
4. 힙의 보안문제로 예를 들어 하나의 프로세스에서 공유하는 단일 힙이 손상된다면 다른 스레드에도 영향이 간다.
멀티힙을 이용하여 하나의 힙이 손상되어도 다른 힙은 그대로 사용이 가능하다.
라고 정리해 볼 수 있다.


line39 의 vTaskDelay 라는 함수는 usleep이라는 함수로 이어진다.
이 usleep이라는 함수는 usleep(1)이라 사용하였다면 1마이크로초를 기다렸다 실행하는 함수 이다.

이는 출력버퍼 안에 있는 데이터를 즉시 출력시켜 버퍼를 비우는 명령이다.